
When newcomers are taking their first steps into container adoption, one of the common areas of confusion is understanding the difference between a container and a virtual machine.
In this blog, I will explain the differences in the technical architecture, and why one is not a direct replacement for the other. Note that this information applies regardless of the orchestrator you may decide to use (Docker or Kubernetes), as it's more about the foundational differences between a VM and a Container.
It's important for newcomers to understand that containers are not automatic replacements for VMs. One of the easiest ways to think of a container is "that a container is just as an application process that runs WITHIN a VM, so how can a container be anything like a VM". This thinking helps to cement the reality that a container is not a replacement for a VM.
But what are the actual differences?
1) Containers are not statically assigned hardware resources, which means you don't need to think about how many CPUs, RAM, disk your application needs to be physically assigned. In a VM, you need to decide upfront, is this a VM with 1,2,4 + CPUs, does it need 1,2,4,8,16+ GB of RAM, do I need 100GB or more disk? And once you deploy your app, to upsizing or downsizing takes a bit of a manual process (how hard/easy depends on your hypervisor / cloud provider).
Containers, by default, have access to ALL of the resources of the VM (host) they are running upon. Sure, you can apply a resource limit, but that's just a software constraint, and requires no downtime.
2) Containers are just a SINGLE process. A container cannot (natively) contain both your front-end application AND your backend DB, unless you knowingly set it up to run this way. Containers also do not run background tasks (such as CRON). When you build your container image, you specify the command (CMD) that the container will run as its PID1 (primary process). As you can see from the MYSQL container image below, the command assigned to PID1 is mysqld.
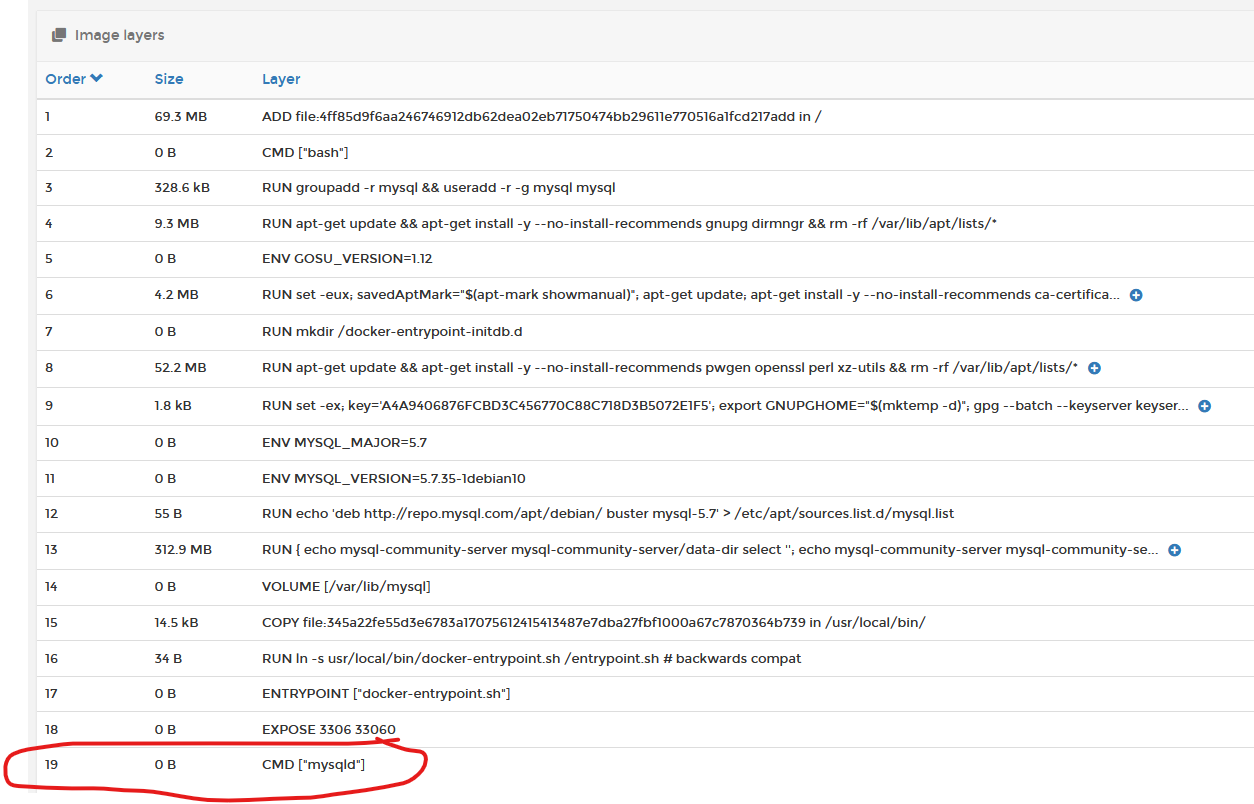
And you can see when the container is running, that mysqld is in fact running as PID1.
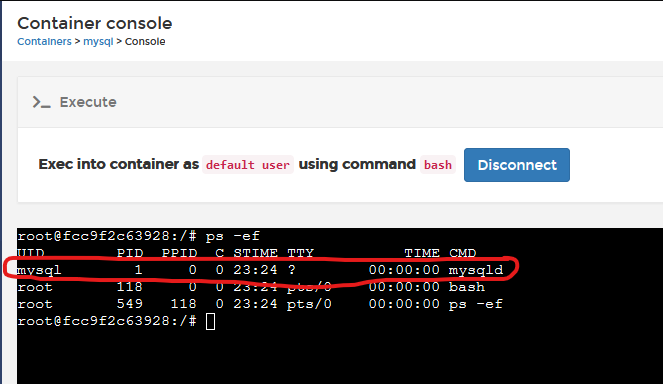
From a mechanical perspective. PID1 is what keeps the container alive. Should PID1 die (or be stopped), the container dies/stops. So whatever process runs as PID1 MUST be a long-running process if you want the container to start and stay running.
If you have a container image that does NOT specify a long-running CMD (PID1), then you must manually specify additional CMD information at container runtime, or else the container will start and then immediately stop (example here is busybox); if you just run it without any other inputs, it starts, executes SH, and then exits. You can make SH wait for inputs by marking the container as being "interactive and TTY" bypassing the -it flags when starting.
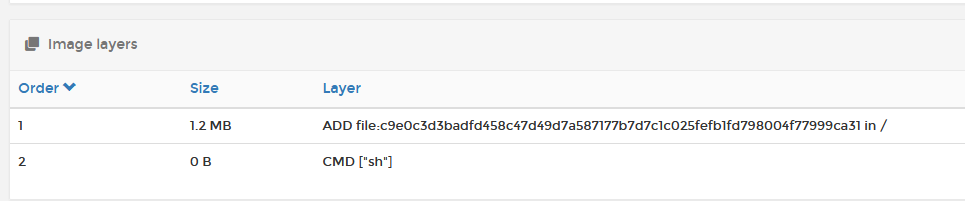
If you deploy as interactive, you can then "attach" to the PID1 instance, and execute commands directly.
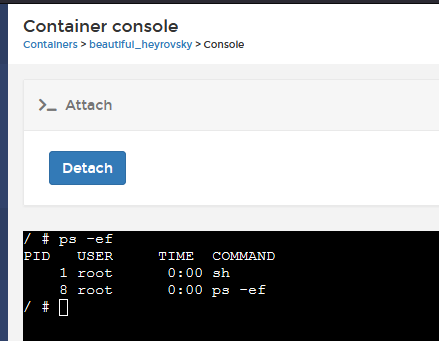
You need to be exceptionally careful here though, as if you happen to send Ctrl Break to this console, you actually kill the SH session, thereby stopping the container (Ctrl C works OK though).
3) Containers are NOT persistent by default. Any changes you make inside the container, are NOT persisted (retained) unless you have knowingly pre-configured the container to run this way at creation time. Inside a container image, the original author would have defined persistent volume requirements, using the VOLUME statement. These are the areas the image creator requires you to make persistent, as this is where the application holds all of its configuration information. If we go back to the MYSQL image example, you can see that the image creator wants you to persist /var/lib/mysql.
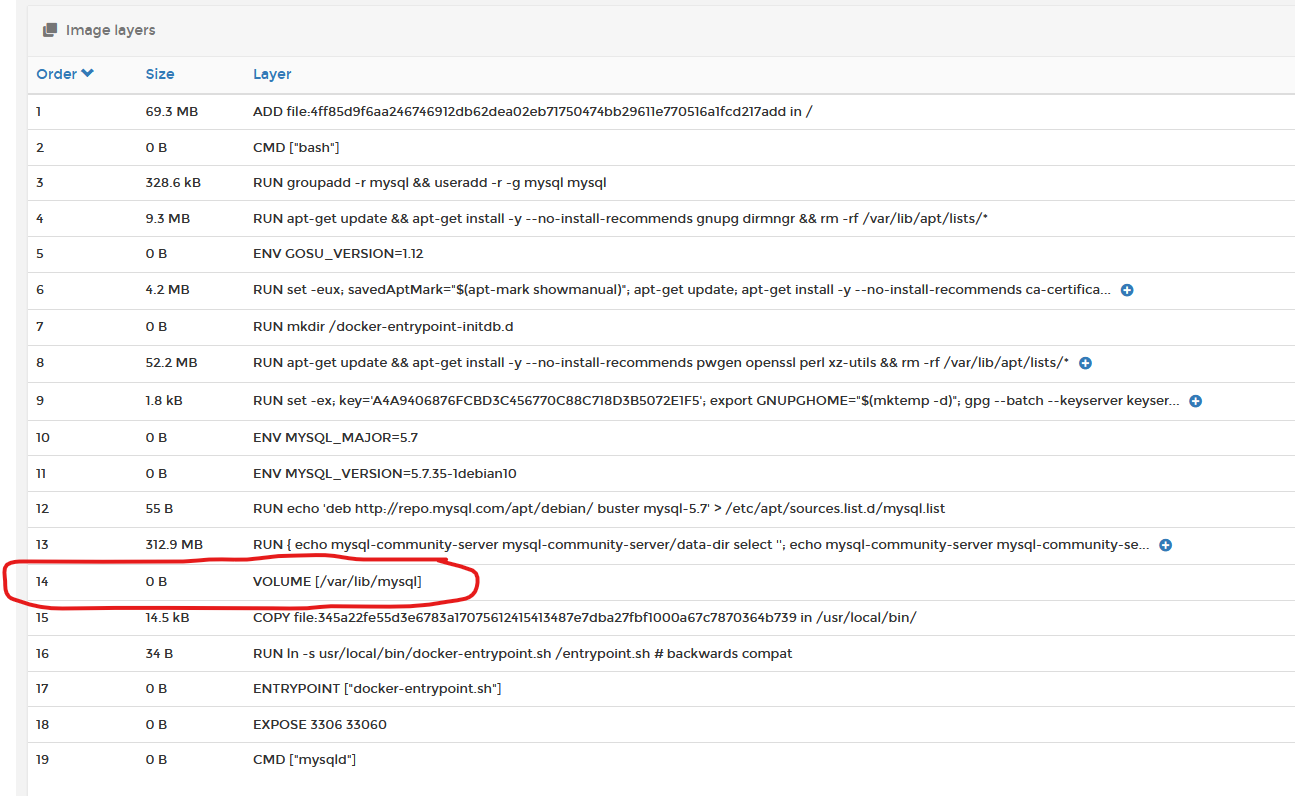
When you deploy your container, you must specify a persistent volume for that container as shown below:
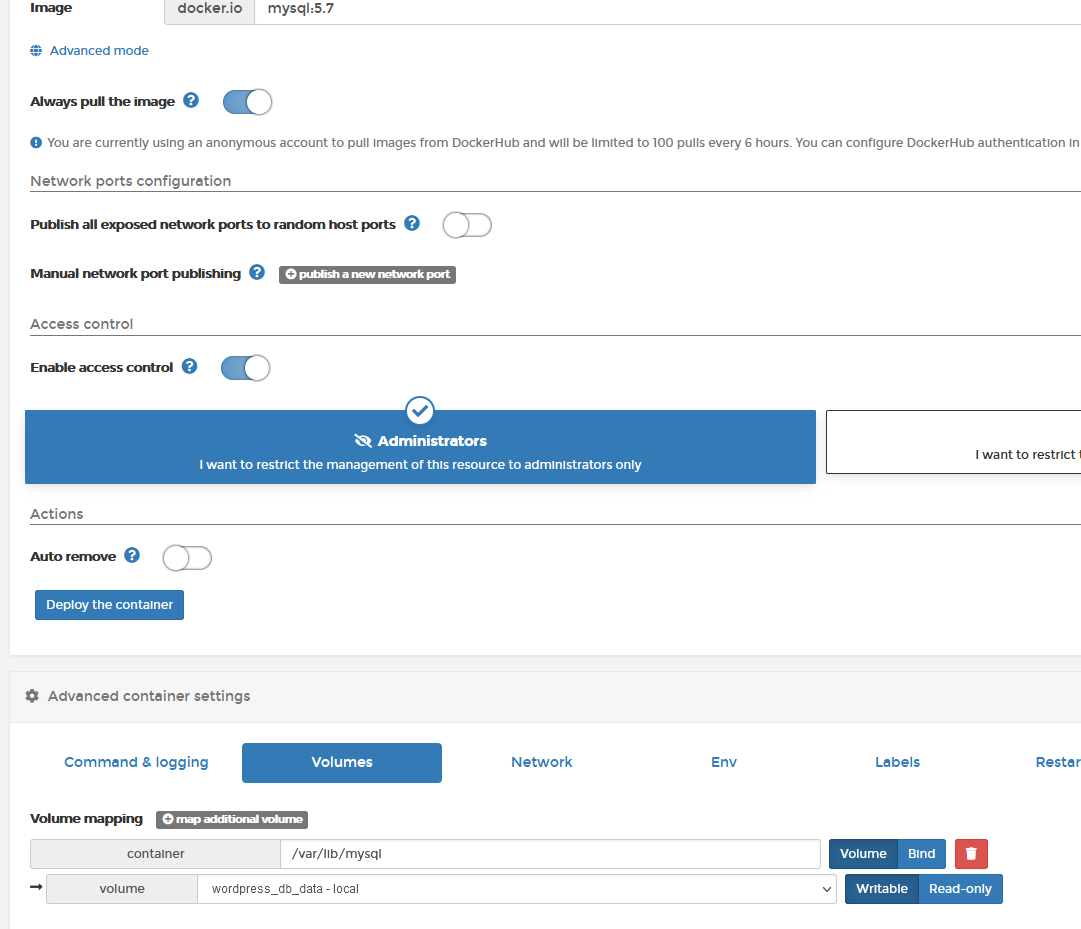
Now, if you happened to console into the container, and run, for example, an apt-get upgrade, to upgrade the software elements inside the container, then this is NOT persisted should the container be updated/redeployed. The only data that is retained is data that resides in the /var/lib/mysql directory.
4) Containers use NAT networking. Containers are, by default, connected to your network by bridging (NAT routing) THROUGH the Docker network interface, so a container itself does not have a "real" IP address on your network. If you deploy a container, it will automatically attach to the "bridge" network, which is the docker network component that implements a NAT router. When you deploy your container, it will get an IP address assigned by the Docker IPAM engine, which by default is in the 172.17.0.0/16 subnet as shown below.
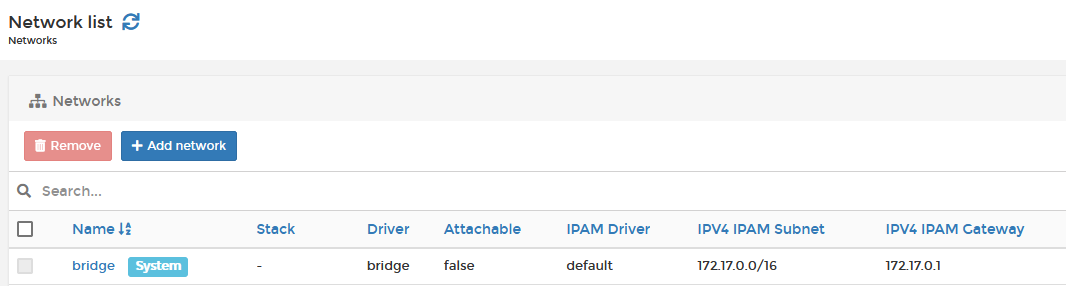
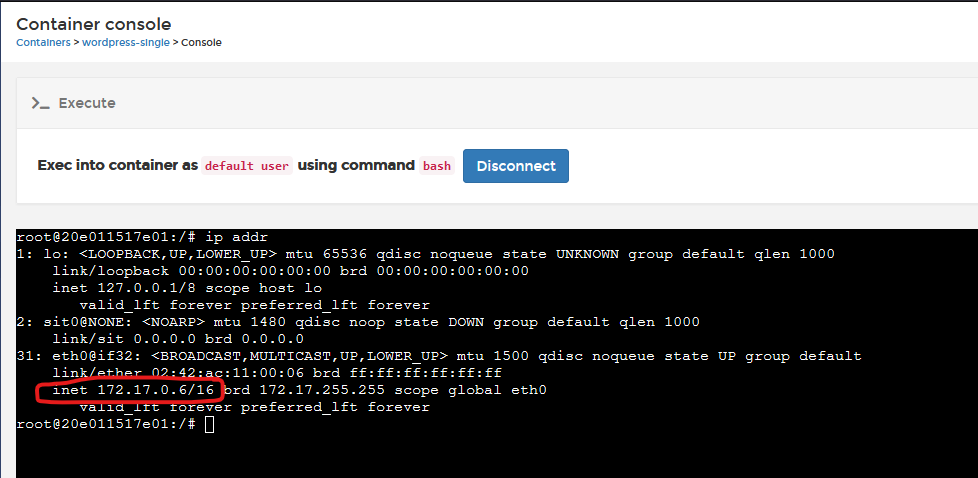
The container I deploy, in my example below, mySQL, has been assigned IP address 172.17.0.6. On my LAN, my networking is 192.168.1.0/24, and I have no way to reach 172.17.0.6, so how do I? By accessing the container using the host's IP address (in my case, my host is 192.168.1.253). This is why, when you deploy a container, you are asked which "ports to publish" as this tells Docker what NAT publishing to automatically configure for you, and its why you cannot have more than one container using any one port (eg just a single container can be assigned Port 80).
So the four points above should highlight why a container is NOT a VM, and how it differs, but what if you want to have your container act like a VM/Virtual Appliance?
Whilst we do not recommend this, the information below may give you some guidance:
1) You CAN run more than one process at a time...
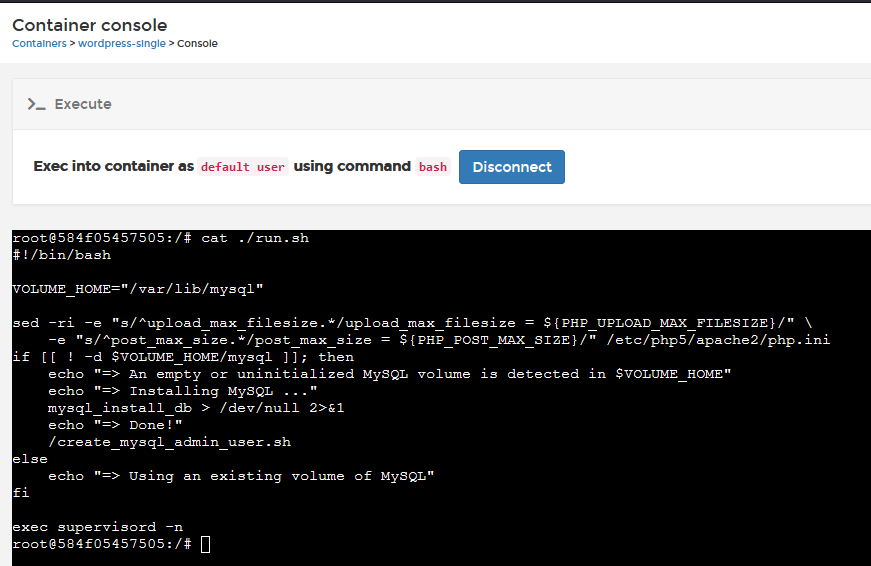
If you want to run something like Wordpress and MYSQL in the same container, you need something to act as PID1, and that something can start and manage the Wordpress and MYSQL processes. This "something" can be as simple as a bash script, that includes an indefinite loop, or a sleep. As you can see from the "Single container Wordpress" image example below (where it's trying to emulate a single VM), they have set a bash script "/run.sh" as their CMD, and that will start a supervisor process to operate as PID1, and then that supervisor starts all of the processes needed, and then sleep.

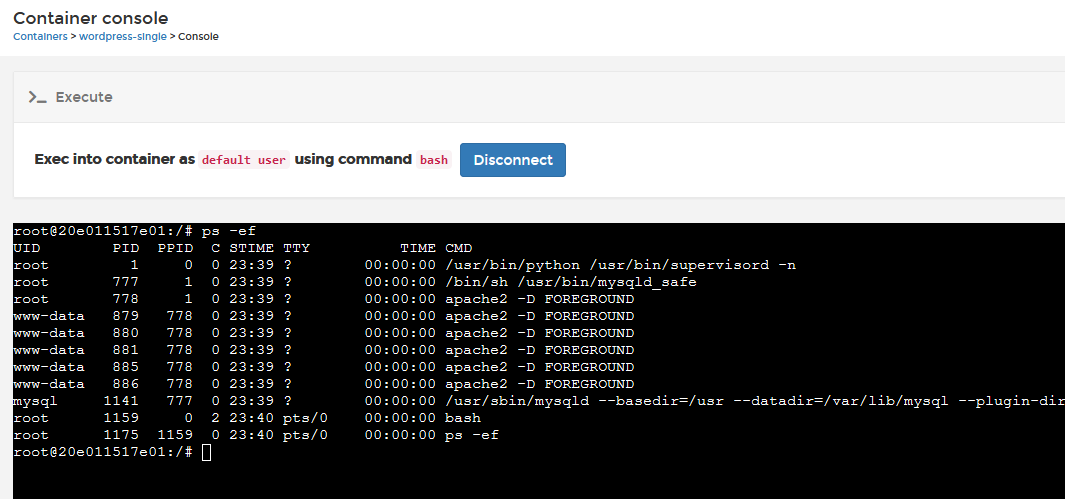
and you can see that supervisord is now PID1 by running a ps -ef
Now, what IS a supervisor process; it's just that, it's a binary/process that runs, stays running, and starts/keeps-alive other processes as defined by its configuration.
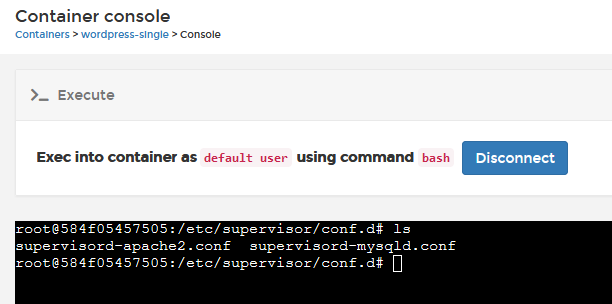
In the example above, it's starting MYSQLD and APACHE2 processes (these are what make up the MSQL app). You can see that by manually running ./supervisorctl from /usr/bin directory in the container console.. You can read more about Supervisord here.

2) You can give your containers a real IP address if you need. Docker (but not Kubernetes) has this awesome network driver called MACVLAN, and basically its a Layer2 pass-through bridge, so that your container can operate on your real network directly. There are some complications here as containers cannot DHCP from your network DHCP server, and your docker host network must be allowed to enter into promiscous mode (most cloud providers explicitly block this, as do some hypervisors). But with MACVLAN your container can be directly routable. To use MACVLAN, you need to configure your Docker Host for it first. Portainer helps you with the process (go into networking, create a network, and select MACVLAN).
3) You can use background task schedulers, like CRON, but you must either make crond your CMD (PID1) or configure your supervisor process to also start crond.

4) Unfortunately there is NO way to make the entire contents of a container persistent, so you either need to manually specify multiple directories to be persisted, or ensure all of your configuration data is stored in a single place, and do not make changes to the container contents directly in the container console.
I hope this helps explain the difference between a container and a VM, and some potential workarounds to get your legacy VM app into a container if you need to do so with minimal changes.
Neil
Try Portainer with 3 Nodes Free
If you're ready to get started with Portainer Business, 3 nodes free is a great place to begin. If you'd prefer to get in touch with us, we'd love to hear from you!


COMMENTS