

Share this post
Ops teams spend over 60% of their time managing Kubernetes on troubleshooting. Not building new services or improving infrastructure, but figuring out what went wrong.
If this sounds familiar, you’re definitely not alone. Kubernetes troubleshooting is one of those things that every team underestimates until they’re staring at a CrashLoopBackOff at 2 a.m., wondering where to even start looking.
The good news, however, is that Kubernetes issues follow predictable patterns. Once you understand how Kubernetes works under the hood and where things typically break, troubleshooting becomes far less reactive and a lot more structured.
This guide covers the most common Kubernetes errors, a practical troubleshooting workflow, and the best practices that help teams resolve issues faster.
What Is Kubernetes Troubleshooting?
Kubernetes troubleshooting is the process of identifying, diagnosing, and resolving issues across your clusters, nodes, pods, and containers. But in practice, it’s less about fixing isolated errors and more about interpreting signals across multiple layers of your environment.
When something goes wrong in Kubernetes, the root cause is rarely where the symptom shows up. A pod stuck in Pending, for example, might appear to be an application issue but actually trace back to insufficient node resources or a misconfigured node selector. A service returning 503s could have nothing to do with the service itself and everything to do with a mismatched label selector between the Service and its target Pods.
This is also what differentiates Kubernetes troubleshooting from traditional infrastructure debugging. You aren’t diagnosing a single server or following a linear path from error to fix. Instead, you’re navigating across workloads, configurations, networking layers, and resource allocations that all interact with each other, often in ways that aren’t immediately obvious.
The teams that troubleshoot effectively aren’t just the ones who know the right kubectl commands. They’re the ones who understand where to look first and why.
Three Pillars of Effective Kubernetes Troubleshooting
Effective Kubernetes troubleshooting comes down to three core disciplines: understanding the problem, managing the resolution, and preventing it from happening again. When applied consistently, these turn reactive firefighting into a repeatable process.
1. Understand
Before you can fix anything, you need to understand what’s actually happening. That means identifying both the symptom and the underlying cause. In practice, this usually involves:
- Scoping the issue. Is it isolated to a single pod, spread across a node, or affecting the entire cluster? The scope determines your next move.
- Reading the signals Kubernetes is giving you. Pod status, events, resource metrics, and logs are all breadcrumbs. A pod in CrashLoopBackOff with an OOMKilled exit code, for example, is telling you something very specific about memory limits.
- Reviewing recent changes. New deployments, config updates, scaling changes, RBAC modifications. With nearly 80% of production incidents tracing back to a recent system change, the question “what changed?” is almost always the right place to start.
- Comparing against a known-good state. Dashboards, monitoring tools, and observability platforms make it significantly easier to spot anomalies when you have a baseline to compare against.
2. Manage
Once you understand what’s causing the issue, remediation should be deliberate. That means applying targeted fixes based on what the diagnostics are actually telling you: adjusting resource limits, correcting a misconfigured probe, rolling back a deployment, or fixing a YAML error.
But how you get there depends on your team’s maturity and the level of documentation in your response processes.
- Ad hoc fixes from engineers with deep component knowledge are fast, but they rely on tribal knowledge and don’t scale.
- Documented runbooks bring consistency and allow any team member to respond effectively, which matters when not everyone has deep Kubernetes architecture expertise.
- Automated runbooks (scripts, IaC templates, or Kubernetes operators that trigger on specific conditions) should be the default where possible, as they reduce human error and significantly cut resolution time.
Regardless of the approach you use, the goal is the same: precision over guesswork.
3. Prevent
This is probably the most overlooked pillar. After resolving an incident, the best teams ask: how do we make sure this doesn’t happen again?
That could mean:
- Adding resource quotas to prevent noisy-neighbor problems.
- Enforcing policy-as-code through admission controllers.
- Tightening RBAC to reduce the blast radius of misconfigurations.
- Implementing GitOps workflows to catch configuration drift automatically before it reaches production.
Beyond the specific fix, this is also the right time to evaluate whether your current monitoring, alerting, and access controls are actually surfacing problems early enough. Prevention is what turns individual fixes into lasting operational improvements.
Why Kubernetes Troubleshooting Is Hard
By design, Kubernetes is complex, and troubleshooting it is no exception. Here are some systemic reasons that even experienced teams find it challenging to troubleshoot:
- Failure signals are often indirect or delayed. Kubernetes will tell you a pod is crashing, but not always why. You have to monitor multiple sources to find the actual cause.
- Shared ownership creates gaps. Application teams, infrastructure teams, and security teams often operate separately, so when an issue spans all three, it falls between the cracks, especially under time pressure.
- Toolchain sprawl. Kubernetes doesn’t come with batteries included. Teams usually inherit an entire ecosystem of tools for observability, CI/CD, and access control, and knowing which one to check first is a challenge in itself.
- Environments drift. Across multiple clusters, teams, and deployment pipelines, configuration drift is almost inevitable. What works in staging can fail in production for reasons that aren’t visible until something breaks.
{{article-cta}}
A Practical Kubernetes Troubleshooting Workflow
If you’re dealing with a Kubernetes issue and aren’t sure where to start, here’s a step-by-step workflow to help you quickly narrow the problem space.
Step 1: Determine the Scope
Start by asking: Is this affecting one pod, one node, one namespace, or the entire cluster? The answer here will shape everything that follows.
A single crashing pod is a very different investigation from a cluster-wide scheduling failure. Run kubectl get pods -A to get a broad view, then run kubectl get nodes to check whether the issue is correlated with a specific node.
If multiple unrelated workloads are failing at the same time, that’s usually a signal to skip ahead to cluster-level health (Step 5) rather than investigating individual pods.
Step 2: Check Workload State
Once you’ve scoped the issue, look at what Kubernetes is telling you about the affected workloads. Run kubectl describe pod <pod-name> and focus on the Status, Conditions, and Events sections.
The status itself narrows your next move. A pod stuck in Pending tells you to investigate scheduling and resources. A pod in CrashLoopBackOff tells you to investigate the application or its configuration. A pod showing Terminating for an unusually long time might indicate a stuck finalizer or a process that isn’t responding to SIGTERM.
The goal here isn’t to fix anything yet, but to categorize the problem so you’re looking in the right place.
Step 3: Validate Configuration
A surprising number of Kubernetes issues stem from a mismatch between what was intended and what was actually applied. This step is about checking whether the deployed configuration matches expectations:
- Resource requests and limits. Are they realistic for the application’s actual usage, or were they copied from a template without adjustment?
- Environment variables and secrets. Is the pod referencing a ConfigMap or Secret that exists in this namespace and has the correct key names?
- Image tags. Is it pulling latest when it should be pinned to a specific version, or vice versa?
- Label selectors. Do the Service selectors actually match the labels on the target pods? A single mismatched label means traffic goes nowhere.
Configuration drift between staging and production is one of the most common and hardest-to-spot causes of production failures. This is also why Kubernetes governance practices are so important.
Step 4: Inspect Logs and Events
If the workload state and configuration both look correct, go deeper into Kubernetes logs and cluster events.
- Application logs (kubectl logs <pod-name> or kubectl logs <pod-name> --previous for crashed containers) reveal runtime errors, unhandled exceptions, and dependency failures like database connection timeouts.
- Kubernetes events (kubectl get events --sort-by=.metadata.creationTimestamp) surface scheduling decisions, probe failures, image pull issues, and resource pressure warnings.
Correlating both gives you the full picture. For example, a pod might show no obvious errors in its logs, but Kubernetes events reveal that its readiness probe has been failing intermittently, causing it to be removed from Service endpoints without actually crashing.
Step 5: Evaluate Cluster-Level Health
If the issue isn’t isolated to a specific workload or configuration, zoom out.
Node-level problems, resource exhaustion, or control plane issues can cause symptoms that look application-level but are actually infrastructure-level.
Check node conditions with kubectl describe node <node-name> and look for pressure indicators: MemoryPressure, DiskPressure, or PIDPressure.
And review cluster-wide resource utilization with kubectl top nodes and kubectl top pods to identify whether the cluster is overcommitted.
For teams managing multiple clusters, a centralized Kubernetes monitoring setup provides visibility across environments, making this step significantly faster than switching between individual cluster contexts.
This is also where platforms like Portainer add real value, giving ops teams a single view across clusters, nodes, and workloads so that cluster-level patterns are visible immediately rather than requiring manual CLI investigation across each environment.
Most Common Kubernetes Errors (and What They Actually Mean)
Not every Kubernetes error requires deep investigation, but most require knowing what you’re actually looking at.
Here are the error patterns ops and platform teams encounter, what they typically point to, and where to focus your attention.
1. CrashLoopBackOff
This is one of the most common Kubernetes errors you’ll encounter. Here, your container keeps crashing, and Kubernetes keeps restarting it with increasing delays between attempts. CrashLoopBackOff itself isn’t the problem, though; it’s a symptom telling you something deeper is failing.
What causes it: Application bugs, misconfigured entrypoints, missing dependencies, or resource limits being exceeded. Start with kubectl logs <pod-name> --previous to see what happened in the last crash. This is usually the fastest path to the actual problem.
2. ImagePullBackOff / ErrImagePull
Kubernetes can’t pull the container image from the registry. You’ll see ErrImagePull on the first attempt, then ImagePullBackOff as Kubernetes retries with increasing delays.
What causes it: A typo in the image name or tag (more often than people would like to admit), the image not existing in the specified registry, or missing imagePullSecrets for a private registry. The Events section in kubectl describe pod will tell you exactly which pull failed and why.
3. OOMKilled
The container was terminated because it exceeded its memory limit. You’ll see exit code 137 and Reason: OOMKilled in the pod description.
What causes it: Memory limits set too low for the application’s actual needs. This happens often when teams copy resource specs from templates without adjusting them to the specific workload. It can also indicate a memory leak or node-level overcommitment. Compare actual usage against configured limits with kubectl top pod to narrow it down.
4. CreateContainerConfigError
The container can’t even start. Something it needs to reference doesn’t exist.
What causes it: A missing or renamed ConfigMap, Secret, or key is almost always the issue. Maybe someone renamed a Secret in one namespace but not another, or there’s a typo in a volume mount path. kubectl describe pod will tell you exactly which resource is missing.
5. Pod Stuck in Pending
The pod has been accepted by the cluster but hasn’t been scheduled to a node. It’s just sitting there, waiting.
What causes it: Insufficient CPU or memory on available nodes are probable reasons for this. But it could also be overly restrictive node selectors or affinity rules, or a PersistentVolume that can’t be bound. If you’re seeing this across multiple pods, it’s usually a sign the cluster needs more capacity rather than a configuration fix.
6. Node NotReady
A node is showing NotReady status, which means the kubelet on that node has stopped communicating with the control plane. This one can be stressful because it potentially affects every workload running on that node.
What causes it: This is frequently caused by node resource exhaustion (disk, memory, or PIDs). Network connectivity issues or a crashed kubelet process can also trigger it. Check kubectl describe node for specific pressure conditions, then investigate kubelet logs on the node itself.
7. Readiness and Liveness Probe Failures
These two get confused a lot, but they do very different things. A failing liveness probe causes Kubernetes to restart the pod. A failing readiness probe removes the pod from Kubernetes service endpoints, causing it to stop receiving traffic but keep running.
What causes it: Probes pointing to the wrong port or path, or initialDelaySeconds set too short for the application’s actual startup time. Misconfigured probes are among the frequent sources of unexpected pod restarts and intermittent traffic drops, and they can be tricky to spot because the pod itself might appear healthy from the outside.
8. RBAC Permission Errors (Forbidden)
A user, service account, or workload gets a 403 Forbidden response from the API server. In plain terms, Kubernetes RBAC is saying, “You don’t have permission to do that.”
What causes it: Missing or misconfigured Role/ClusterRoleBindings. This often happens after role changes, when a new service account hasn’t been granted the right bindings, or when namespace-scoped roles are applied but the request targets a cluster-scoped resource. The error message usually specifies the exact verb and resource being denied, which tells you precisely where to look.
{{article-cta}}
Best Practices for Effective Kubernetes Troubleshooting
The workflow and error patterns covered above will help you resolve issues faster in the moment. But the teams that spend the least time troubleshooting are the ones that invest in making it easier before something breaks.
- Standardize your environments. Configuration drift between staging and production is a common source of hard-to-diagnose failures. Use GitOps workflows to enforce consistency across clusters through policy rather than tribal knowledge. Portainer supports this with built-in GitOps integration and security constraints across all your Kubernetes environments.
- Centralize visibility across clusters. Switching between cluster contexts and CLI sessions during an incident wastes critical time, and for teams already stretched thin across multiple clusters and environments, that context-switching is where burnout compounds. A single view across all your environments makes a real difference, not just operationally, but for the people doing the work.
- Invest in logging and monitoring before you need it. The worst time to set up observability is during an incident. Make sure your logging, metrics, and alerting infrastructure are in place and tested well before production issues hit.
- Define clear ownership. When an issue spans application code, infrastructure, and security, the biggest delay is often figuring out who should be looking at it. Define which team owns which namespaces, services, and clusters, and document escalation paths.
- Apply the principle of least privilege. Overly permissive access creates security risk and makes troubleshooting harder, because the blast radius of any misconfiguration is wider than it needs to be. Portainer makes this practical with predefined Kubernetes RBAC roles scoped to clusters and namespaces, so teams can enforce least privilege without writing custom policies from scratch.
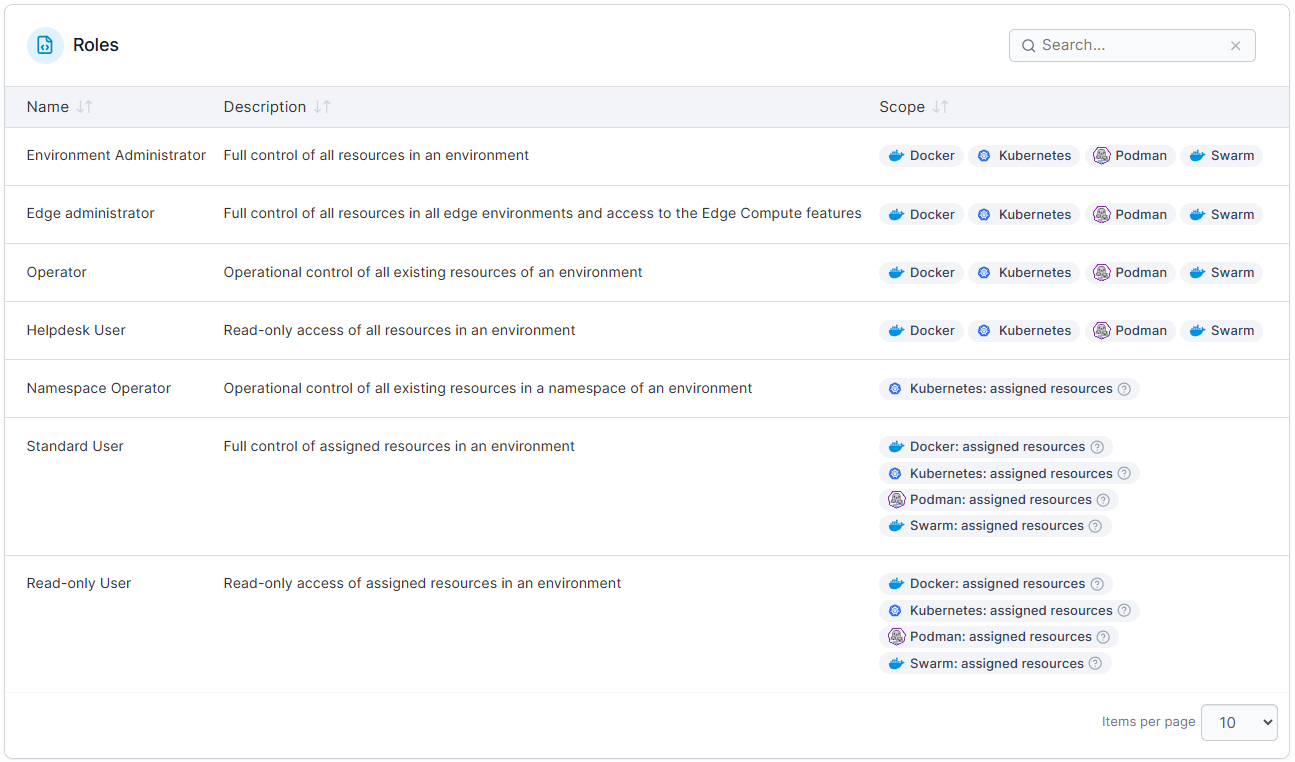
- Use runbooks and automate where possible. If your team has seen the same issue more than twice, document a runbook. Better yet, automate the response. Automated remediation for predictable failure patterns reduces MTTR and frees your team to focus on problems that require human judgment.
- Run postmortems, then act on them. A postmortem that doesn’t result in action is just documentation. Identify what broke, why it wasn’t caught earlier, and what specific change will prevent it from recurring. The best teams treat this as a platform engineering best practice, not just an incident review.
Reduce Kubernetes Firefighting with Better Visibility and Control
Kubernetes troubleshooting problems tend to share a common thread: too many tools, too many layers, and not enough visibility across all of them.
The teams that resolve issues fastest and stay ahead of the next one are those with centralized visibility, consistent policies, and clear access controls across all clusters and environments.
Portainer is a lightweight, self-hosted, vendor-agnostic container management platform that gives ops and platform engineering teams a single interface for Kubernetes, Docker, and Podman. It also provides multi-cluster visibility, built-in RBAC, GitOps integration, and governance controls without the complexity or cost typically associated with full-scale enterprise platforms.
For teams that don’t need the operational overhead of an OpenShift or Rancher deployment, Portainer offers the same core visibility and governance capabilities in a lighter footprint
If your team is spending more time troubleshooting than building, schedule a demo to see how Portainer gives your team centralized control across every environment.



