

Share this post
The global edge computing market is projected to grow from $658.1 billion in 2026 to $1.87 trillion by 2031, expanding at a 23.2% CAGR. A major reason for that growth is enterprises moving workloads from centralized cloud clusters to factory floors, retail branches, remote field sites, and other distributed infrastructure.
The problem is, managing containers across those environments isn’t anything like managing them in the cloud. Connectivity drops, sites go offline, and the tooling that works fine in a data center starts falling apart.
Edge orchestration solves this by automating the deployment, update, and management of containerized workloads across distributed edge environments from a single control plane.
This guide covers how edge orchestration works, the architectural models behind it, why standard Kubernetes tooling often breaks at the edge, and how to evaluate a platform that holds up across distributed sites.
What Is Edge Orchestration?
Edge orchestration is the layer that coordinates how containerized applications are scheduled, deployed, monitored, and updated across distributed edge sites from a centralized control plane.
Think of it as container orchestration adapted for environments where the assumptions of cloud infrastructure (stable networking, abundant compute, co-located clusters) no longer apply.
In practice, an edge orchestration platform manages the complete lifecycle of workloads running on devices and nodes at remote locations. This includes:
- Pushing configuration and application updates to edge sites
- Enforcing consistent security and access policies across every node
- Reconciling drift when a site reconnects after going offline
- Scaling workloads across geographically scattered infrastructure
So how does this differ from standard Kubernetes orchestration?
Kubernetes orchestration assumes all nodes live within a well-connected cluster with reliable networking between them. Edge orchestration, on the other hand, doesn’t make that assumption. It accounts for nodes sitting behind firewalls, running on constrained hardware, or losing connectivity for hours at a time.
Understanding that distinction is important because the architecture powering edge orchestration is built specifically around those constraints.
How Edge Orchestration Works
Edge orchestration follows a consistent pattern regardless of platform: define the desired state centrally, push it outward, and continuously enforce it at every remote site. Four components make this work.
1. Central Control Plane
The control plane is where operators declare what should run, where it should run, and under what policies. This is the declarative model at the core of edge orchestration.
Rather than configuring each site individually, teams define the desired end state once, and the system handles its distribution across all edge environments.
In practice, the control plane is where teams:
- Create and assign deployment definitions to specific edge groups or sites
- Set resource limits, security constraints, and governance rules
- Enforce consistent RBAC and access policies across the entire fleet
- Aggregate health data, status updates, and event logs from every connected node
Everything flows outward from here. Instead of logging into individual sites to make changes, operators push intent from the control plane and let the system distribute it.
This is also where centralized visibility lives, giving operations teams a single view of what’s running across the fleet without needing direct access to each node.
2. Edge Agent
Each remote site runs a lightweight agent that acts as the local executor. The agent receives instructions from the control plane, applies them to the local environment, and reports state back.
This is what makes edge orchestration fundamentally different from managing a single centralized cluster.
The agent operates independently, so if connectivity to the control plane is lost, the site doesn’t go down. Workloads keep running based on the last known desired state, and the agent queues any pending updates until the connection is restored.
The autonomy here is critical as edge footprints continue to grow. In fact, an estimated 75% of enterprise-generated data is now created and processed outside traditional data centers or cloud environments, up from roughly 10% just a few years ago. As more workloads shift to the edge, agents that can function without a constant connection to the control plane are what keep distributed sites operational.
The agent also handles local concerns like:
- Container lifecycle management (starts, stops, restarts)
- Health checks and log collection
- Initiating outbound connections to the control plane, which eliminates the need to open firewall rules at remote sites
Together, these responsibilities mean the agent is the runtime backbone of each edge site.
3. Reconciliation Loop
The reconciliation loop is the mechanism that keeps edge sites in sync with what the control plane expects. It runs on a continuous cycle: the agent compares the actual state of the local environment against the desired state defined centrally and corrects any drift it finds.
This means:
- If a container crashes, the loop restarts it
- If someone manually changes a configuration on-site, the loop reverts it to match the declared state
- If a deployment was updated while a site was offline, the loop reconciles the gap once the agent reconnects
This is the same GitOps principle that drives tools like ArgoCD and Flux in cloud environments, but adapted for sites that might only sync intermittently. Instead of requiring a constant connection to enforce state, the loop works on whatever schedule the connectivity allows.
This continuous enforcement is what allows teams to manage hundreds of edge sites without manually auditing each one. The loop handles compliance automatically, flagging or correcting deviations as they occur rather than waiting for an operator to catch them.
4. Connectivity Layer
Everything above depends on a connectivity layer built to tolerate the realities of distributed infrastructure: dropped links, high latency, bandwidth constraints, and in some cases, complete air-gaps.
Unlike cloud-native orchestration where reliable, low-latency networking is a given, edge computing orchestration platforms have to assume connectivity will be unreliable. This means the connectivity layer needs to support:
- Store-and-forward messaging, queuing commands until a site reconnects
- Asynchronous communication patterns so sites aren’t blocked waiting for a response
- mTLS or equivalent encryption for securing data in transit across untrusted networks
- Minimal bandwidth consumption to work over cellular or satellite links
The connectivity layer is often the clearest dividing line between platforms that work in a lab demo and platforms that actually hold up in production across dozens or hundreds of remote sites. If the orchestration layer can’t tolerate unreliable networking, everything built on top of it becomes fragile.
Types of Edge Orchestrators
Not every edge environment has the same constraints, so not every orchestration architecture works the same way. There are three primary models, each defined by the structure of the relationship between the central control plane and edge sites. The right choice depends on scale, connectivity conditions, and the level of autonomy each site needs.
Quick Comparison
1. Centralized
In a centralized model, all orchestration logic lives in a single control plane. Every edge site receives instructions from this hub, reports state back to it, and depends on it for scheduling, policy enforcement, and lifecycle management.
This is the simplest architecture to operate and the one used by most commercial edge orchestration platforms in production today. One control plane means one place to define policies, one dashboard for visibility, and one source of truth for the desired state across every site.
For teams managing edge locations with reasonably stable connectivity, centralized orchestration keeps overhead low and multi-cluster management straightforward.
Take, for example, a logistics company running containerized tracking and routing applications across 80 regional warehouses. Each site has stable broadband, the workloads are uniform, and the operations team needs a single interface to push updates and monitor health.
A centralized model gives them exactly that: one control plane to deploy across all 80 sites, track status in real time, and enforce consistent configurations without any intermediate layers adding complexity.
Where it gets challenging:
- Sites with unreliable or intermittent connectivity become harder to manage, since the control plane can’t push updates or pull status consistently
- As the number of edge sites grows into the hundreds or thousands, the central hub can become a bottleneck for scheduling and state reconciliation
- If the control plane goes down, edge sites continue running on their last known desired state, but operators lose the ability to push changes, enforce updated policies, or get fleet-wide visibility until it recovers
Centralized works well for enterprise IT teams running edge infrastructure across a manageable number of locations with decent network access. It’s the default starting point for teams adopting edge orchestration for the first time.
2. Hierarchical
A hierarchical model builds on the centralized approach by adding intermediate layers. A top-level control plane handles fleet-wide policy, governance, and visibility, but delegates execution to regional hubs or intermediate orchestrators that each manage a cluster of edge sites beneath them.
This gives teams the benefits of centralized governance (consistent RBAC, audit logging, and access controls) without funneling every operation through a single point. Regional hubs can continue operating even if the top-level control plane goes temporarily offline, and they reduce the blast radius of any single failure.
Take a manufacturing company operating 12 plants across three continents, for example. Each continent has a regional orchestrator managing the plants in its geography, while a global control plane sets company-wide security policies and aggregates visibility.
If the connection between Europe and the global hub drops, the European regional orchestrator keeps its four plants running and synchronized independently. The global team doesn’t lose governance over the fleet, and the regional sites don’t lose operational continuity while the connection recovers.
Where it gets challenging:
- Each regional hub is another orchestrator to maintain, upgrade, and monitor, which increases the operational overhead for infrastructure teams
- Requires careful design around how policies cascade from the top level down through regional hubs to individual sites
- Troubleshooting becomes harder when issues can originate at any layer in the hierarchy
Hierarchical works well for large-scale distributed deployments where both governance and high availability matter. Think manufacturing networks spanning multiple plants, retail chains with regional clusters, or telecom infrastructure spread across geographies.
3. Distributed (Peer-to-Peer)
In a fully distributed model, there is no central control plane. Each edge site operates as an autonomous unit with its own orchestration logic, making local scheduling and lifecycle decisions independently. Sites can optionally sync state with each other through peer-to-peer coordination, but no single node controls the fleet.
This architecture is designed for environments where connectivity to any central hub is either too unreliable or too latent to depend on. Each site handles its own workload placement, scaling, and failure recovery without waiting for instructions from elsewhere.
It’s worth noting that fully distributed edge orchestration is far more common in academic research and highly specialized environments than in mainstream enterprise tooling. The coordination overhead of keeping autonomous nodes aligned without a central authority is significant, and the tradeoffs in governance and visibility are hard to justify for teams that need consistent policy enforcement across sites.
Where it gets challenging:
- Enforcing consistent security standards and governance across sites becomes significantly harder without a central authority
- Fleet-wide visibility requires aggregating data from every independent node, which adds complexity
- Coordinating deployments or rollbacks across multiple sites simultaneously is difficult when no central orchestrator is directing the process
Distributed works in environments where site-level autonomy is the top priority, like remote industrial locations, offshore platforms, or field deployments where each site operates in complete isolation for extended periods. For enterprise IT teams, this model rarely makes practical sense as a primary architecture.
Why Cloud-Native Orchestration Breaks at the Edge
According to a Dimensional Research study, 72% of Kubernetes users said it’s too challenging to deploy and manage Kubernetes on edge devices.
The core reason is straightforward: Kubernetes was built for data centers with stable networking, abundant compute, and nodes that live within well-connected clusters. Extending that same tooling to edge environments means fighting against those assumptions at every step.
Here’s where it breaks down:
1. It Assumes Always-On Connectivity
The Kubernetes control plane requires constant communication with worker nodes. Here’s what happens when that communication drops:
- The API server can't reach nodes for scheduling, health checks, or state updates
- etcd, the underlying datastore, requires low-latency consensus across the cluster to function correctly
- Nodes that lose connection get marked as “NotReady,” and if the disconnection persists, Kubernetes starts evicting pods from them entirely
In a data center, this is the right behavior. If a node is unreachable, something is probably wrong, and rescheduling workloads elsewhere is the safe move. At the edge, however, connectivity drops are a normal operating condition.
Kubernetes doesn’t distinguish between the two. It treats a satellite link blipping for ten minutes the same way it treats a failed server, actively tearing down workloads that were running fine on healthy hardware.
2. The Resource Footprint Is Too Heavy
Standard Kubernetes requires a minimum of 4GB of RAM per control plane node, plus separate etcd clusters, networking components, and monitoring overhead. A minimal production cluster can easily consume 8 to 12GB before a single application workload is deployed.
Edge devices, on the other hand, often run on 512MB to 2GB of RAM with a limited CPU. The control plane overhead alone can consume the device’s entire capacity, leaving nothing for the actual workloads it’s supposed to run.
Lightweight Kubernetes distributions like K3s and MicroK8s address this by stripping out heavy components and replacing etcd with SQLite, but they’re mostly workarounds for a platform that wasn’t designed for these constraints in the first place.
3. No Multi-Site or Fleet Awareness
Kubernetes is designed to manage a single cluster. It has no native concept of site grouping, fleet-wide rollouts, or coordinating deployments across hundreds of independent edge locations.
For a team managing 200 retail locations, this means managing 200 separate clusters with no unified layer above them. There’s no built-in way to:
- Push a configuration update to all sites at once
- Group sites by region, environment type, or hardware profile
- Roll out application updates incrementally across a subset before expanding fleet-wide
Each cluster is its own island. Any coordination across them requires external tooling, custom scripting, or a dedicated management platform layered on top.
4. The Failure Recovery Model Doesn't Translate
In a data center, Kubernetes handles node failures by rescheduling pods to another available node in the cluster. There are usually dozens or hundreds of interchangeable nodes to choose from, and the system is designed to find one automatically.
In an edge environment, this model falls apart. A node running on a factory floor, in a retail store, or at a cell tower is often the only node at that site. There’s no nearby rack to reschedule to. As the Linux Foundation has noted, you can’t tell Kubernetes to go find another computer when the workload is tightly bound to a specific physical device at a specific physical location.
The failure recovery strategy has to shift from “reschedule elsewhere” to “keep running locally and recover in place,” and standard Kubernetes doesn’t support that pattern.
5. The Security Model Assumes Trusted Networks
Kubernetes exposes its API server within a trusted, internal network. Nodes communicate with the control plane over low-latency, private connections where network-level security is a reasonable baseline assumption.
At the edge, however, this assumption simply doesn’t hold. Nodes sit behind firewalls, connect over cellular or satellite networks, or operate in physically unsecured locations. Exposing the API server to inbound connections from these environments creates a significant attack surface.
The model needs to be inverted: edge nodes should initiate outbound connections to the control plane, not the other way around. Kubernetes doesn’t support this pattern natively, which means teams either build custom networking solutions around it or accept a security posture that doesn’t match the reality of their deployment.
{{article-cta}}
How to Choose an Edge Orchestration Platform
If you’re evaluating edge orchestration platforms for a distributed deployment, the decision factors below map directly to the challenges covered earlier in this guide. Here’s what to look for.
1. Offline and Intermittent Connectivity Support
The first thing to evaluate is how the platform handles connectivity loss. It’s common for edge sites to go offline, links to drop or satellite and cellular connections to fluctuate. The platform you choose needs to treat this as a normal operating condition.
Look for agents that operate autonomously when disconnected, queue pending updates until connectivity returns, and reconcile state automatically on reconnection. If the platform requires a constant connection to the control plane to function, it won’t hold up at scale across distributed sites.
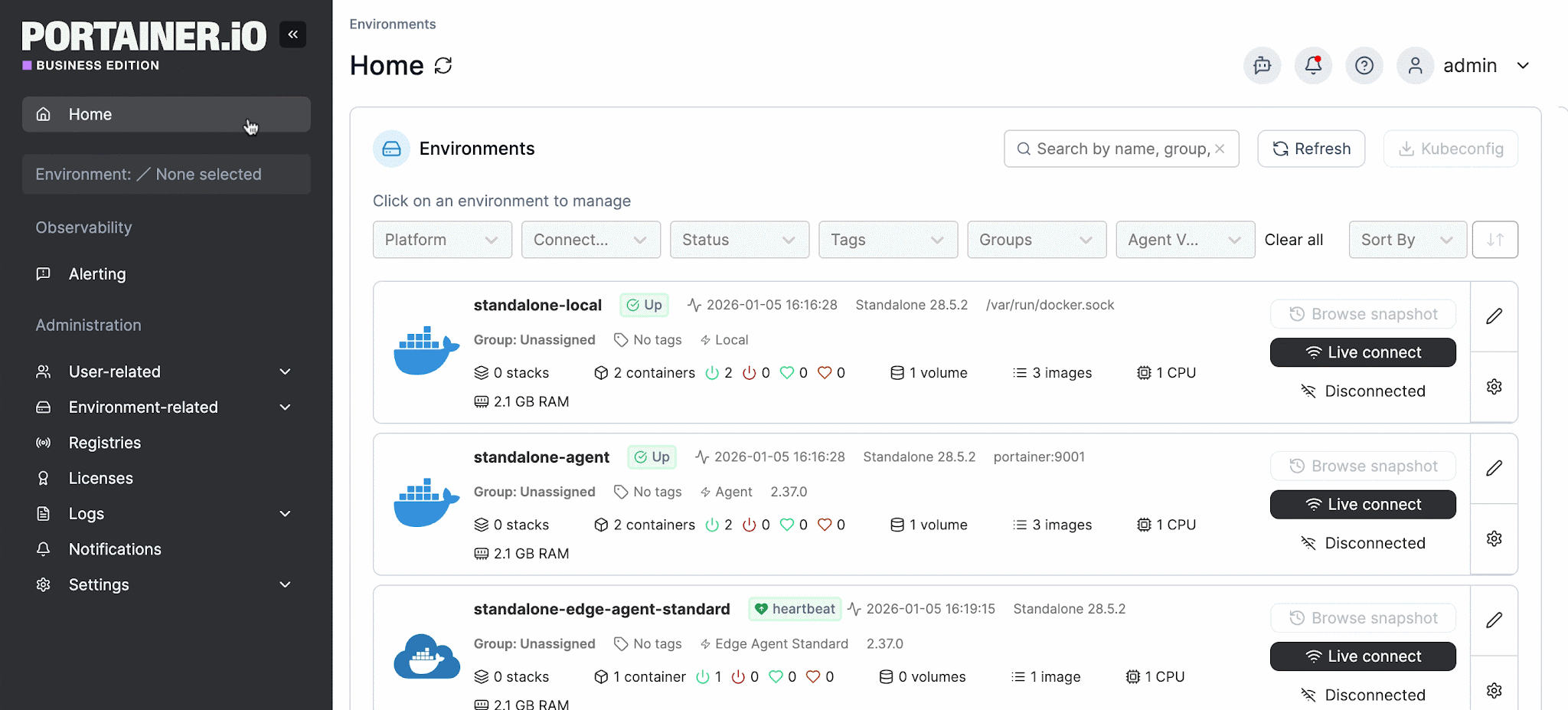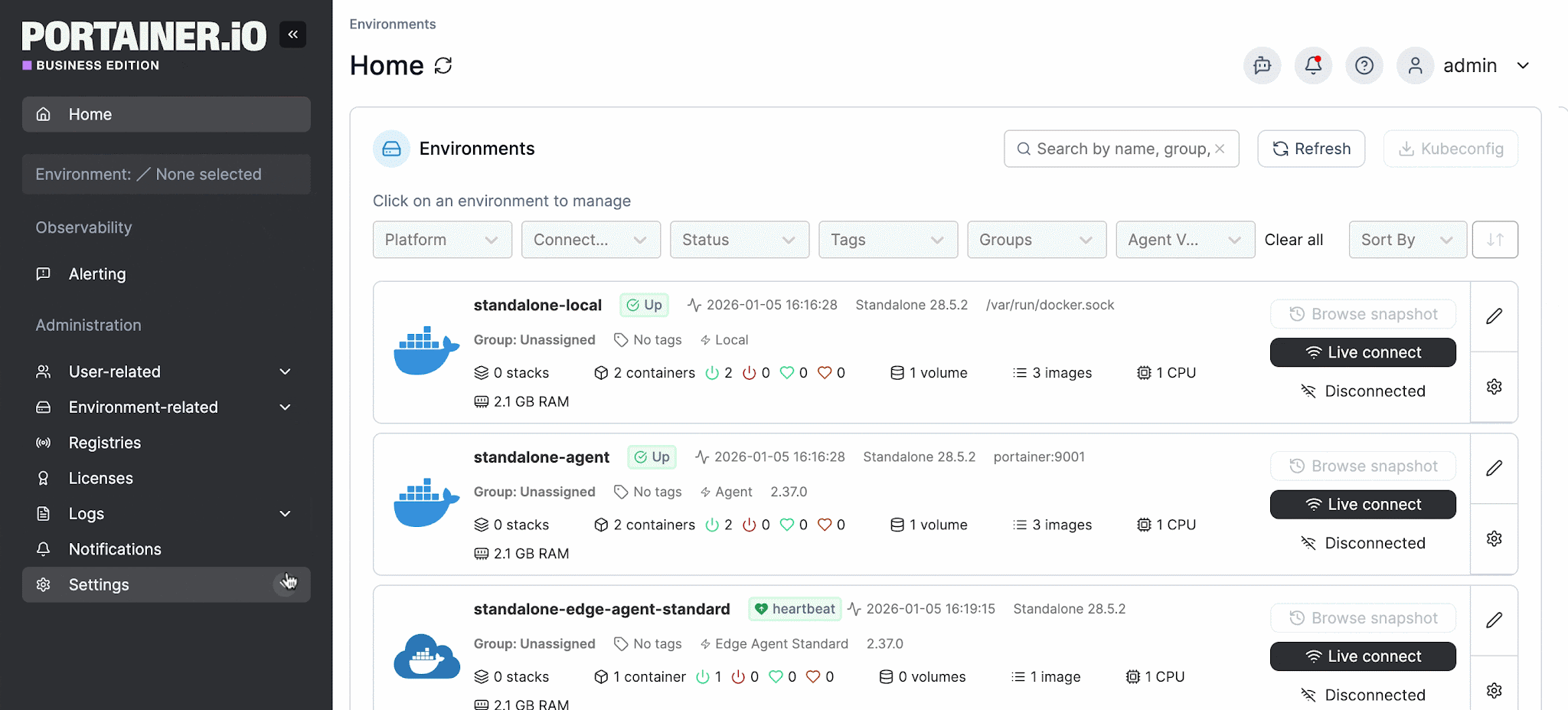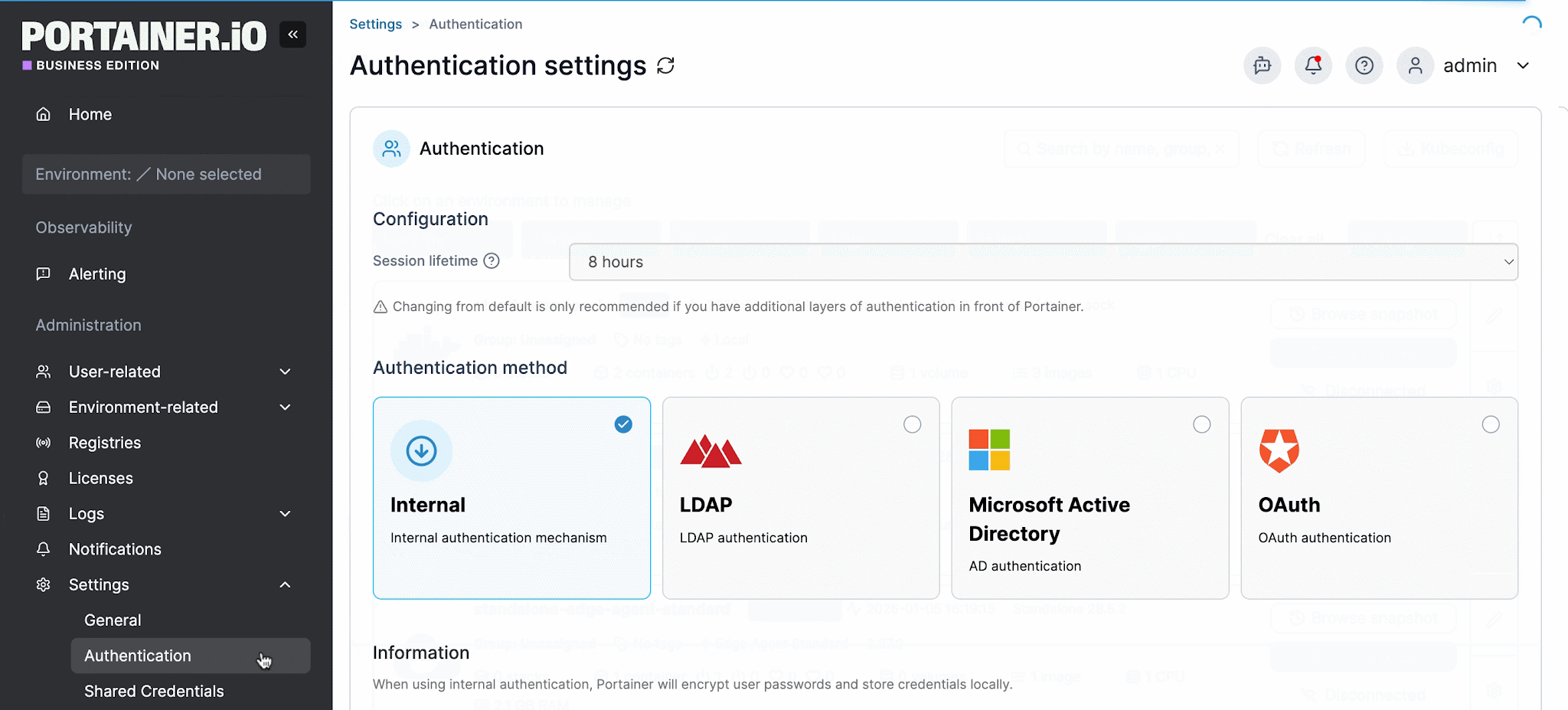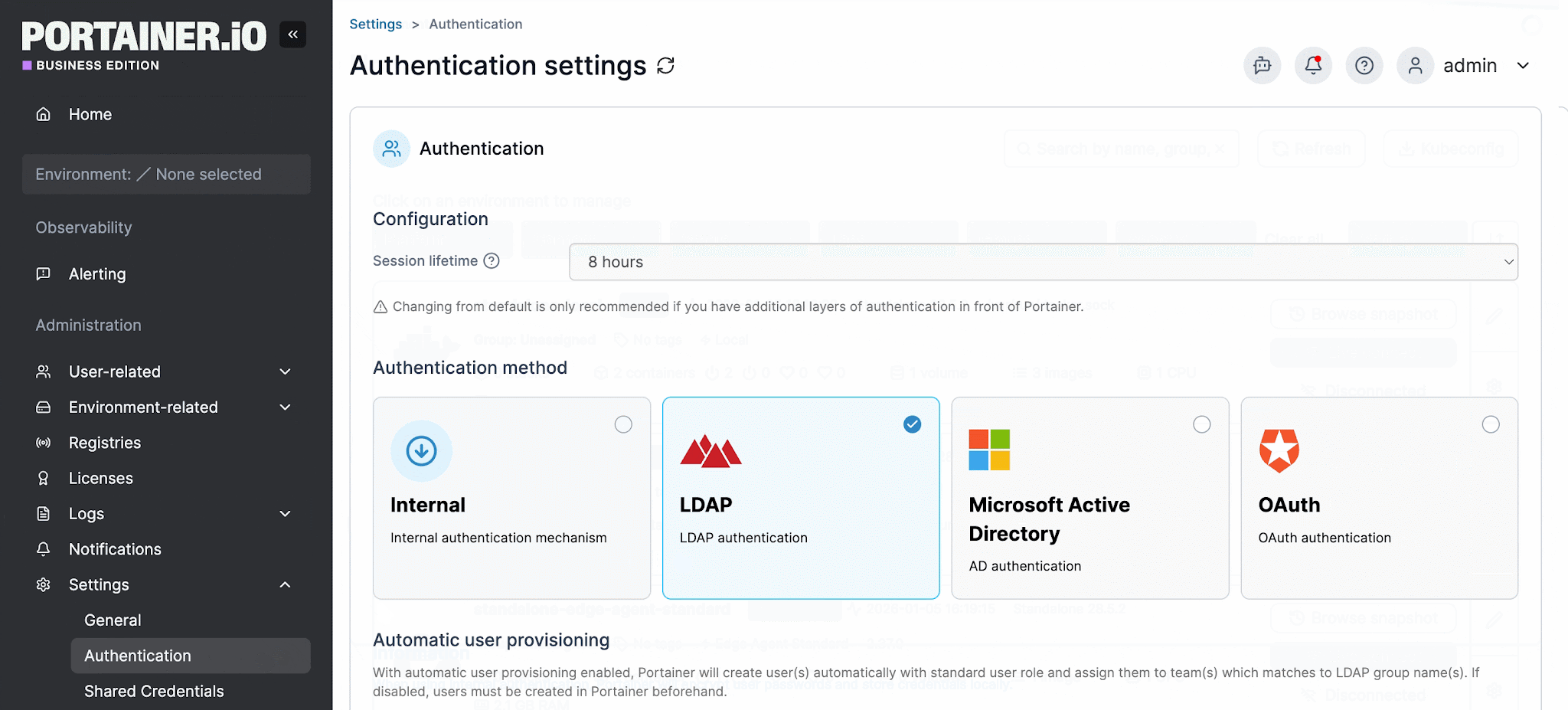
Portainer addresses this with two Edge Agent modes:
- Standard Edge Agent: polls the Portainer server at configurable intervals and continues operating independently during connectivity loss
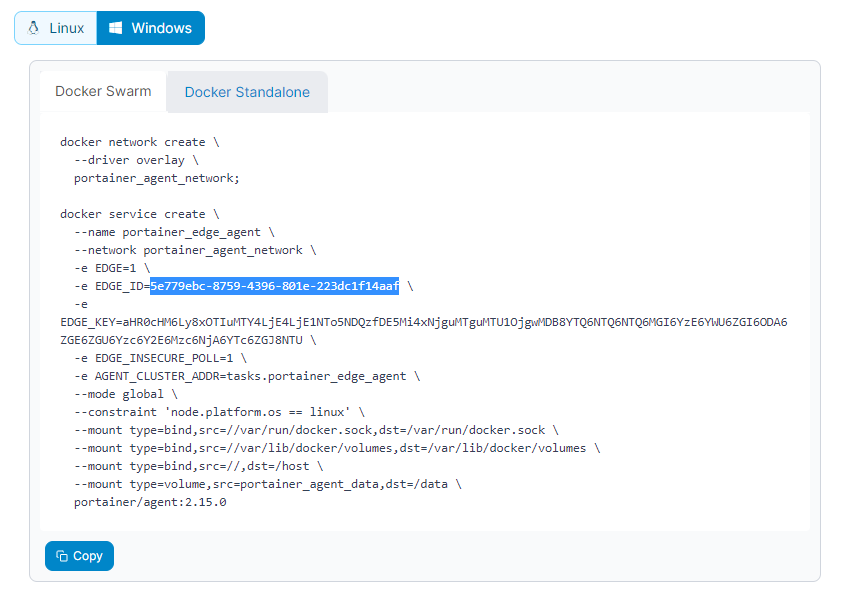
- Async Edge Agent: designed for severely constrained or intermittent connectivity, working entirely through periodic snapshots and queued commands with minimal bandwidth and no persistent tunnel required
Both modes ensure that edge sites continue operating normally during connectivity loss, with updates applied automatically once the connection is restored.
2. Resource Footprint at the Edge
Edge hardware is often constrained. Devices running at factory floors, retail locations, or field sites might have 512MB to 2GB of RAM and limited CPU. If the agent or runtime consuming those resources is too heavy, there’s nothing left for the actual workloads.
Evaluate how much overhead the platform introduces at each edge site. The lighter the agent, the more capacity remains available for production applications. Also look at the central management layer: some platforms require heavy management clusters that add infrastructure cost and operational burden.
Portainer’s Edge Agent is lightweight by design. The central Portainer instance itself can manage thousands of environments while consuming as little as one vCPU and 2GB of RAM. This keeps the resource overhead low at every layer, both at the edge site and at the central control plane. Portainer’s Edge/IIoT pricing tier is structured for exactly this kind of distributed fleet deployment, rather than the per-cluster models built for centralized cloud infrastructure.
3. Fleet-Wide Management and Visibility
Managing edge sites individually doesn’t scale. Once the fleet expands beyond a handful of locations, teams need the ability to group sites, push updates to targeted subsets, and monitor health across the entire fleet from a single place.
Look for platforms that support site grouping (by region, environment type, hardware profile, or custom tags), fleet-wide deployment with phased rollouts, and centralized dashboards that aggregate status and health data without requiring direct access to each node.
Portainer provides this through Edge Groups and Edge Stacks. Teams define groups based on tags or environment metadata, assign stacks to those groups, and deploy consistently across every site in the group from a single interface.
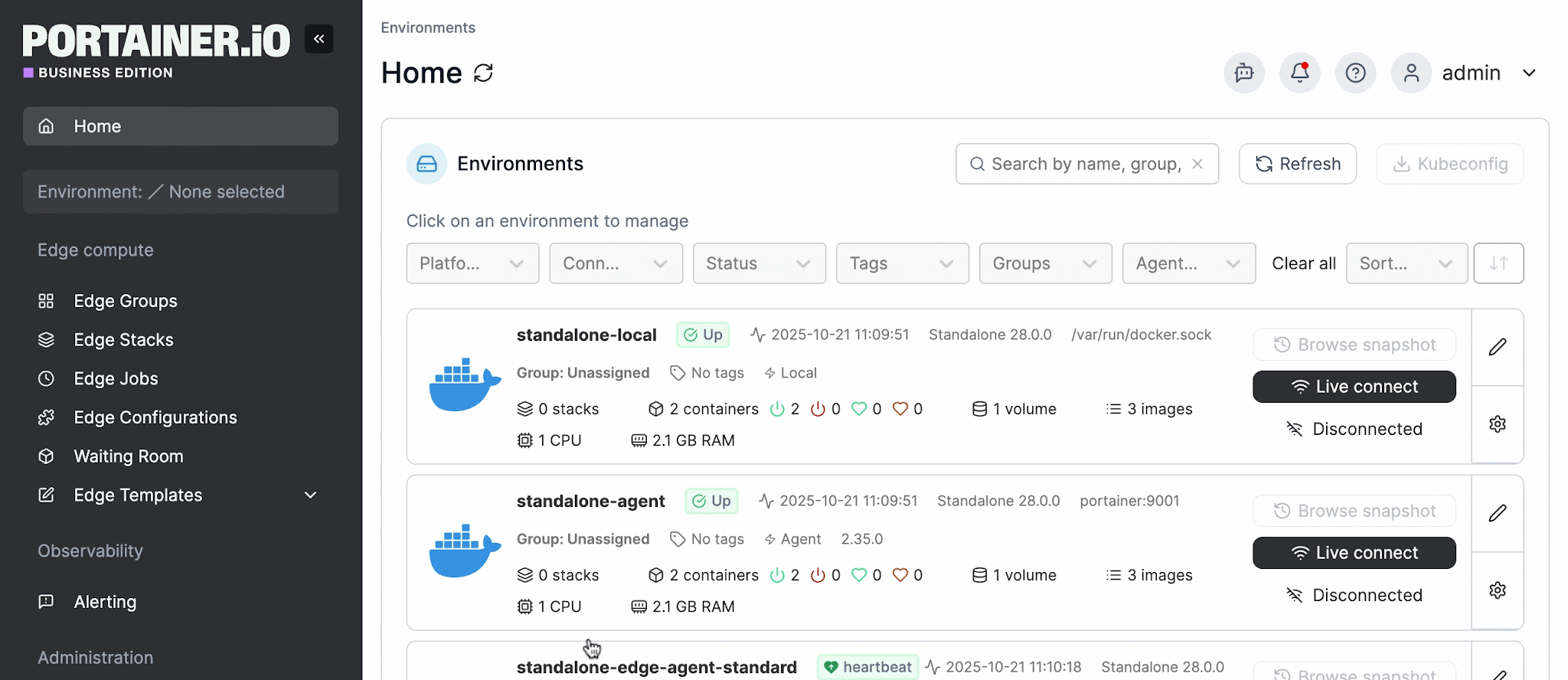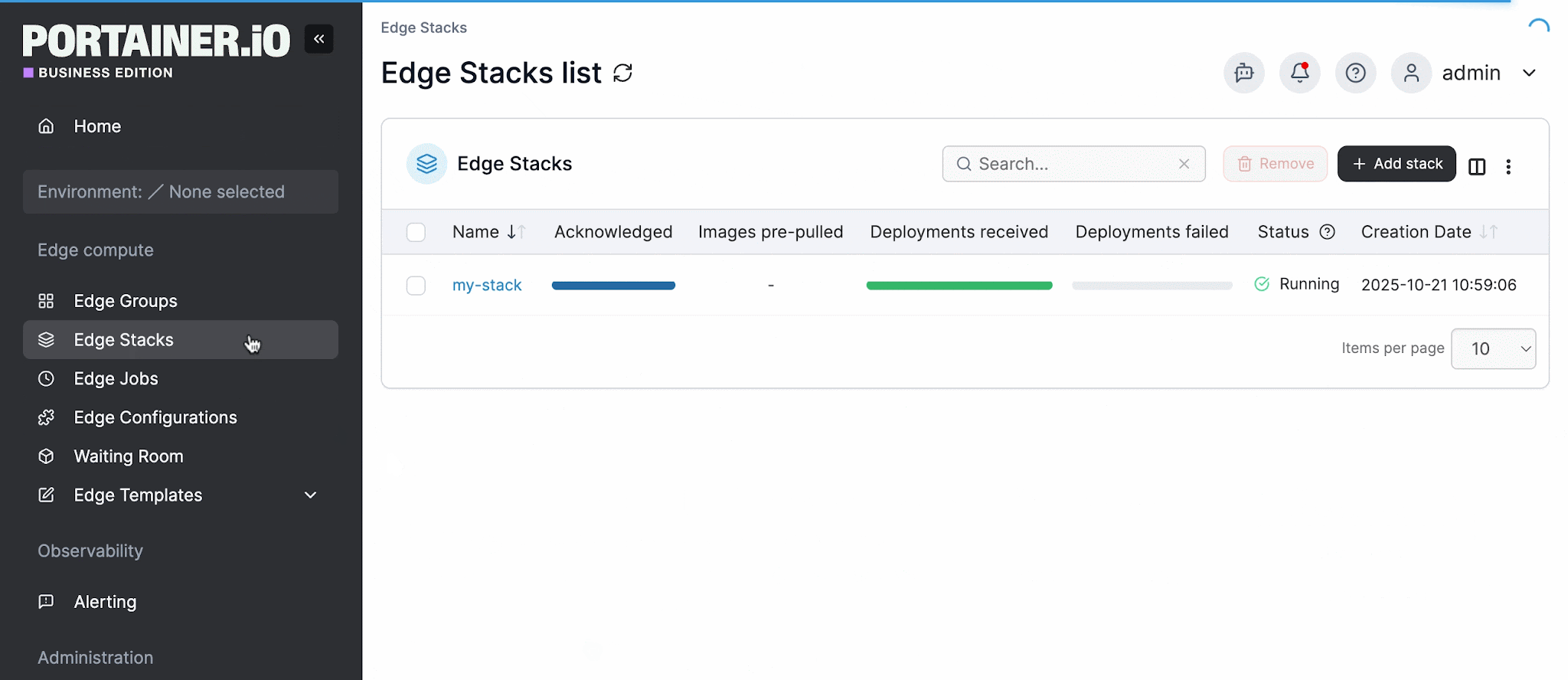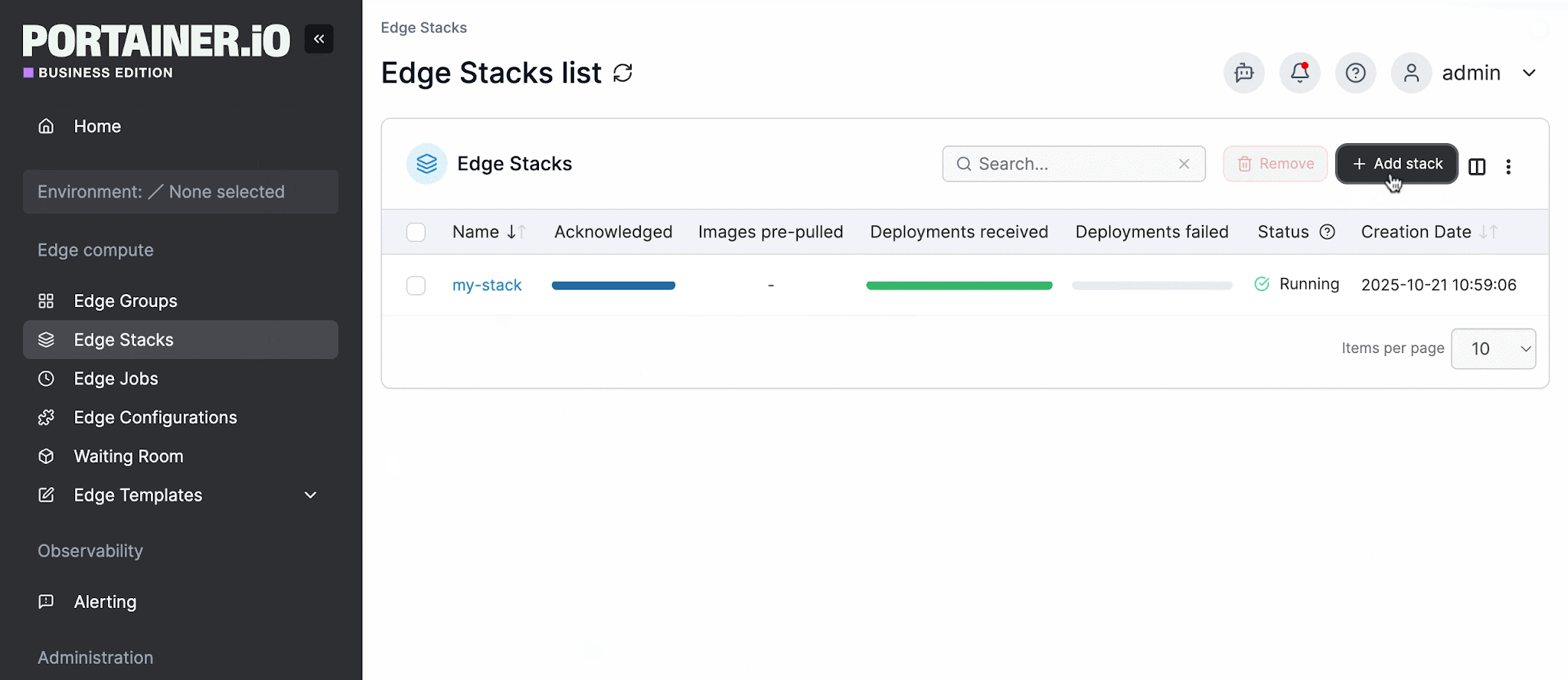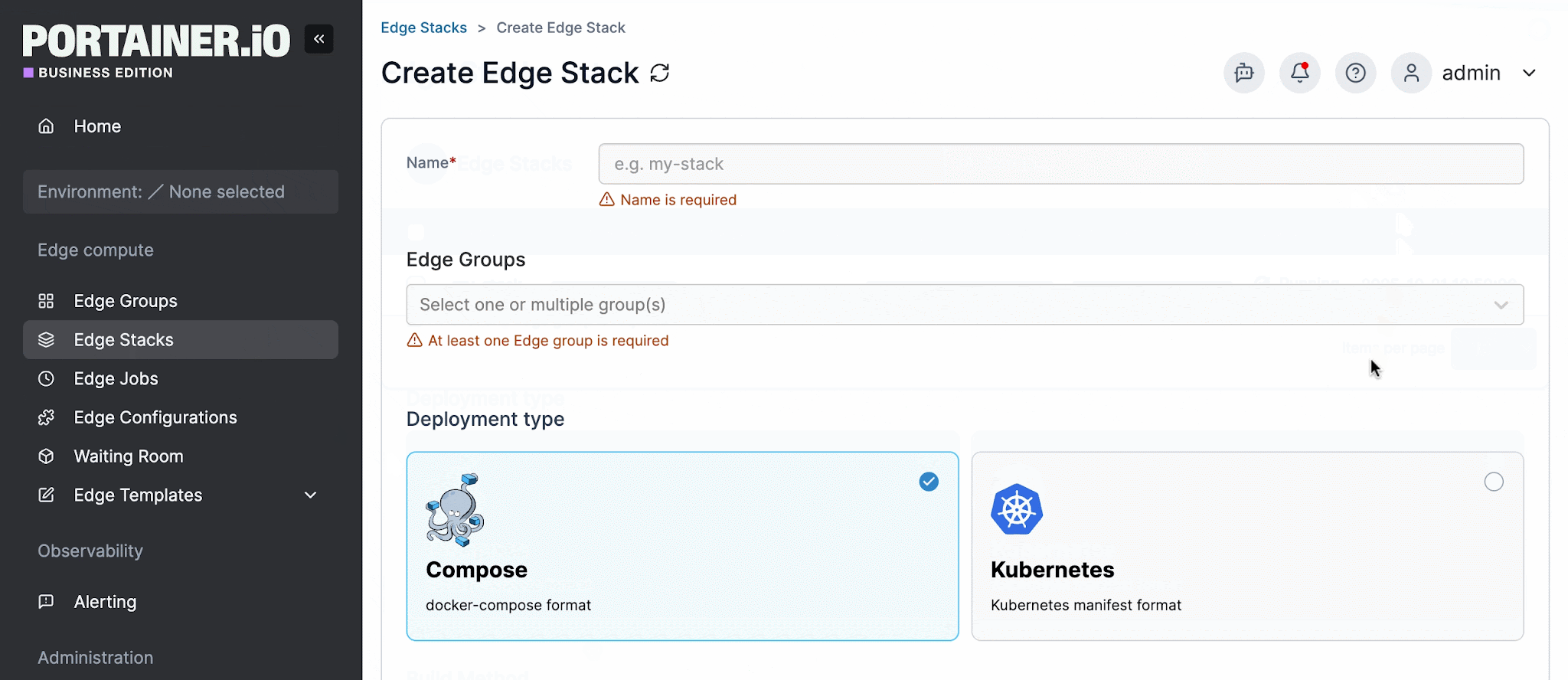
Rollouts can be configured as parallel (static group sizes or exponential) with configurable timeouts and delays between batches. The centralized dashboard shows the status of every connected environment at a glance, with the ability to drill into individual sites when needed.
Because Portainer is vendor-agnostic, the same control plane manages Docker, Kubernetes, Podman, and Swarm environments across any infrastructure, so a mixed- or multi-cloud edge fleet doesn't lock you into a single provider or runtime.
4. Security for Untrusted Networks
Edge nodes operate in environments that are fundamentally different from a data center network. They sit behind firewalls, connect over public or cellular networks, and in some cases run in physically unsecured locations. The platform’s security model has to account for all of this.
Evaluate whether the platform supports:
- Outbound-only agent connections, so no inbound firewall rules need to be opened at remote sites
- Encrypted communications via mTLS or equivalent for mutual authentication
- The ability to operate in air-gapped or restricted network environments
Portainer’s Edge Agent initiates all connections outbound to the Portainer server. No inbound ports need to be opened at the edge site, and all communication is encrypted via TLS.
For environments requiring additional security, mTLS can be configured to provide mutual authentication between the agent and the control plane.
5. Governance and Access Control at Scale
As edge fleets grow, so does the risk of configuration drift, unauthorized changes, and inconsistent policies across sites. The platform needs to enforce governance centrally without requiring manual auditing of each individual location.
Look for:
- RBAC scoped by role, team, or environment
- Audit logging that captures who changed what, when, and where
- Integration with corporate identity providers (LDAP, Active Directory, SSO) to avoid managing users separately inside the platform
Portainer provides centralized RBAC with predefined roles scoped to clusters or namespaces, and includes a dedicated Edge Administrator role for teams managing edge-specific resources.
All user actions are logged for auditability, and authentication integrates directly with LDAP, Active Directory, and OAuth providers, keeping access control consistent with the organization's existing identity structure.
6. Deployment and Operational Simplicity
Edge orchestration platforms that require extensive Kubernetes expertise to set up and maintain create the same bottleneck they’re supposed to eliminate. If only a small number of specialists can operate the platform, it won’t scale with the fleet.
Evaluate how quickly teams can get from installation to first deployment. Look for UI-driven workflows, form-based application deployment, and guided setup processes that don't require writing YAML from scratch or managing complex CLI tooling.
Portainer can be deployed as a single lightweight container and be operational within minutes. Application deployment is available through a visual form-based interface, Helm charts, raw YAML, or GitOps workflows from a connected repository.
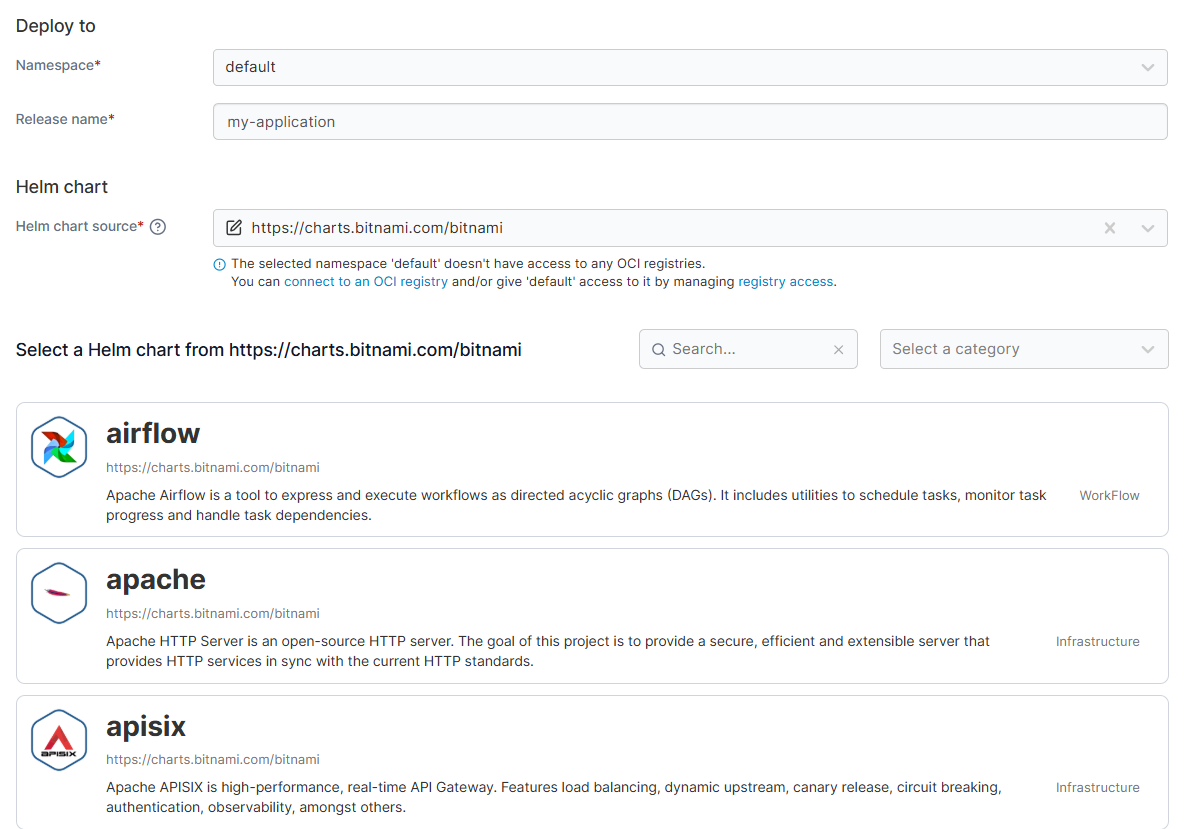
This means platform engineers, IT generalists, and operations teams can all manage edge workloads without requiring specialized Kubernetes training.
Portainer: The Management Layer for Edge Orchestration at Scale
Portainer gives enterprise IT and operations teams a single control plane to deploy, manage, and secure containerized workloads across distributed edge environments, without requiring deep Kubernetes expertise at every site.
With lightweight Edge Agents (standard and async), centralized fleet management through Edge Groups and Edge Stacks, built-in RBAC and audit logging, and a UI that IT generalists can operate from day one, Portainer is designed for the realities of edge infrastructure: constrained hardware, unreliable connectivity, and distributed sites that need to run independently.
It delivers enterprise-grade governance, RBAC, and audit capabilities without the overhead or the specialist headcount that edge orchestration at this scale typically demands.
Want to see how these capabilities work across your edge infrastructure? Book a demo with Portainer’s technical sales team.
{{article-cta}}
FAQs
1. What industries benefit from edge orchestration?
Manufacturing, retail, energy, telecommunications, and logistics are among the primary adopters. Any industry operating containerized workloads across multiple physical locations with varying connectivity conditions is a strong fit.
2. Is edge orchestration the same as edge computing?
No. Edge computing is the broader practice of processing data closer to where it’s generated. Edge orchestration is the management layer that automates the deployment, updating, and maintenance of containerized applications across edge computing environments.
3. Can edge orchestration work with existing cloud Kubernetes clusters?
Yes. Teams can manage both cloud-based and edge-based clusters from the same orchestration platform, which is especially useful during migrations or hybrid deployments where workloads span both environments.

.png)

