

Share this post
The conversation around Kubernetes at the edge has been heating up, but with it comes a common question:
“Why push something as heavy as Kubernetes all the way down to the device edge? Isn’t Docker or Podman enough?”
The short answer:
Docker is enough for single, isolated containers. But it isn’t enough for the way modern software vendors now deliver real, production-grade applications. More and more of these applications are being shipped as Kubernetes Operators. But Operators don’t run on Docker. They run on Kubernetes.
This shift is exactly why we created KubeSolo: a minimal, single-node flavor of Kubernetes designed specifically for edge hardware, capable of running Operators without the overhead of a full cluster.
KubeSolo makes Kubernetes at the edge not only possible, but practical.
Why Kubernetes at the edge is becoming necessary
The industry shift toward Kubernetes Operators
Modern commercial software vendors, especially in IoT, industrial automation, and distributed systems, are increasingly packaging their products as Operators.
Operators:
- Manage full lifecycle automation
- Reconcile desired vs. actual state
- Handle scaling, recovery, configuration, and updates
- Embed vendor operational expertise directly into Kubernetes
Operators depend on CRDs (Custom Resource Definitions). You declare something like:
kind: HiveMQCluster
and the Operator builds out the entire application stack.
This packaging model is becoming the default way vendors ship software. If your infrastructure can’t run Operators, you can’t deploy modern edge applications in a supported or automated way.
This is the root reason Kubernetes is moving to the edge.
Why traditional edge runtimes aren’t enough
Docker/Podman works… until it doesn’t
If you’re running a single containerized sensor, small API, or one-off service, Docker is fine.
But when you’re deploying:
- vendor-supplied MQTT clusters
- multi-component analytic pipelines
- distributed edge gateways
- sidecars, proxies, and HA topologies
- software that must self-heal and self-manage
…Docker and Podman fall short. They offer no native reconciliation loop, no Operators, no CRDs, and no declarative automation.
The edge increasingly demands autonomous, self-healing, vendor-supported application stacks, not just containers.
The K2D experiment
When we first encountered the problem, Kubernetes wasn’t even in the conversation, because Kubernetes simply didn’t fit at the Industrial Edge.
Edge devices were:
- isolated
- intermittently connected
- resource constrained
- dependent on physical redundancy instead of control-plane HA
Full Kubernetes clusters were too heavy, too complex, and too demanding for those environments. So organizations deployed containers using Docker because that was all the hardware and topology could support.
But while users stayed on Docker, vendors began standardizing on the Kubernetes API. Helm became the default installation method. CRDs became the standard extension mechanism. Operators assumed RBAC. Docker alone could not consume the ecosystem that was forming.
Our first attempt to solve this mismatch was K2D.
K2D acted as a translation layer. It ran on top of Docker, listened for Kubernetes API calls, and translated them into Docker operations. It allowed edge devices to pretend they understood Kubernetes, even though they were still running Docker under the hood.
This worked… for a while. But it was ultimately a compromise.
You ended up living in two worlds: Kubernetes on the outside, Docker on the inside. Docker remained the underlying runtime, so you never gained the real Kubernetes feature surface - only a compatibility layer. And as the Kubernetes ecosystem grew more Operator-centric, that translation gap widened.
K2D taught us an important lesson: The industry didn’t need a translator. It needed Kubernetes itself, just without the cluster.
Why Kubernetes at the edge works (when done right)
The edge is hostile. Kubernetes was designed for hostility.
Device-edge environments are messy:
- Networks drop
- Devices reboot
- Bandwidth is constrained
- Human intervention is rare
- Thousands of nodes may be geographically distributed
Operators thrive here because they constantly reconcile:
desired state → actual state
If a pod dies, a config resets, or a node restarts, the Operator fixes it automatically. At the edge, this isn’t a “nice to have”: it’s survival. However, automation still requires oversight, and using a dedicated IoT device management dashboard ensures that platform teams have real-time visibility into these automated self-healing events.
The reason Kubernetes wasn’t used at the edge before was overhead, not capability. Strip away the overhead, and you unlock a perfect match.
Real vendors are already shipping Kubernetes-native edge software
This is not theory. Many vendors in IoT, industrial automation, and large-scale distributed systems already ship Operator-based deployments:
HiveMQ
A production-grade MQTT broker. Their Operator provisions clusters, manages TLS, scales the system, and maintains resilience.
EMQX
High-throughput MQTT platform used in industrial settings. The Operator handles cluster orchestration and automated scaling.
Cumulocity IoT
Deploys a full industrial IoT edge gateway stack via a Kubernetes Operator, from pipelines to cloud connectors.
Dapr
A lightweight application runtime widely used in distributed IoT device management topologies. Managed and kept consistent via its Operator.
These workloads are designed for automation, consistency, and self-healing - all core Kubernetes properties. Without Kubernetes at the edge, you simply cannot deploy these solutions properly.
Introducing KubeSolo: Kubernetes at the edge, without the bloat
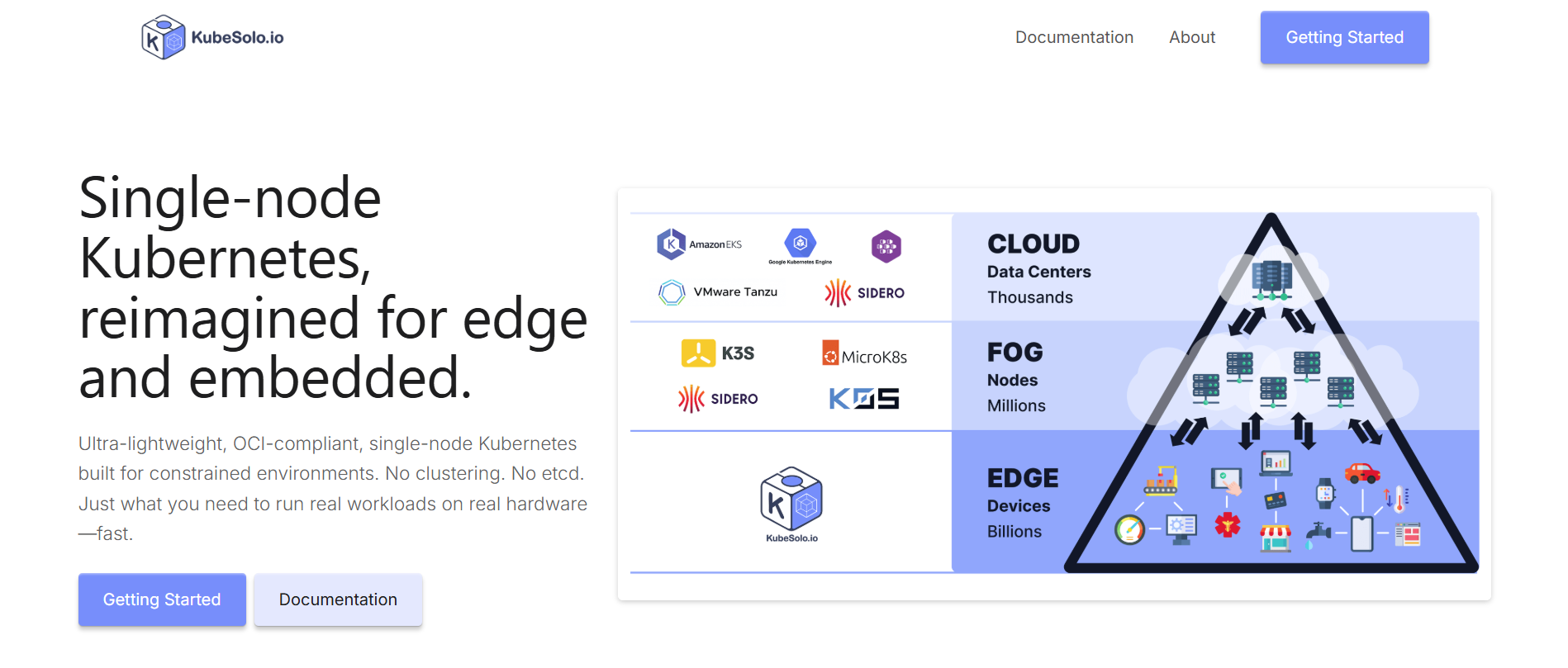
Why we built it
KubeSolo exists because translating Kubernetes (like we did with K2D) wasn’t enough. The world had already standardized on the Kubernetes API. Docker’s simplicity was still appealing, but its API was no longer where the ecosystem was building.
So we stripped Kubernetes down to what matters on a single node:
You get:
- the Kubernetes API the ecosystem expects
- Helm
- CRDs
- Operators
- RBAC
- Namespaces
- declarative deployments
You skip every component that only exists for clustering:
- scheduler
- etcd quorum
- replicated control plane
- overlay networking for large clusters
- complex lifecycle tooling
KubeSolo is designed to bring Kubernetes to constrained edge devices without the weight of a full cluster:
- Single-node Kubernetes
- Minimal memory footprint
- Minimal disk I/O
- No clustering complexity
- Supports CRDs and Operators fully
- Integrates cleanly with multi-cluster management platforms (including Portainer)
KubeSolo turns edge hardware into a first-class Kubernetes target, enabling you to deploy modern software exactly as vendors intend. It doesn’t just simulate Kubernetes like K2D did, it is Kubernetes, just without the clutter.
What Kubernetes at the edge changes for platform teams
Once your edge devices run Kubernetes (via something lightweight like KubeSolo), everything gets dramatically simpler and more scalable.
1. A Unified Deployment Model
Deploy to cloud, datacenter, and edge with the same tools and patterns.
2. GitOps Everywhere
Use one CI/CD pipeline from dev to production to edge.
3. Consistent Observability
CRD .status fields, metrics, and logs behave the same across environments.
4. Uniform Security + Policy
Apply the same governance patterns to thousands of distributed nodes.
5. True Self-Healing at the Edge
Operators keep systems running even when humans aren’t nearby.
6. Vendor Compatibility
Most importantly:
You gain the ability to run modern Kubernetes-native applications at the edge.
If your edge platform cannot run Operators, it cannot run what the industry is now building.
Why Kubernetes at the edge is now practical
Ten years ago: Kubernetes was too new, too immature.
Five years ago: Kubernetes had matured, but was still too heavy for the edge.
Today: With KubeSolo and similar ultra-light distributions, the equation has changed.
KubeSolo brings:
- Single-node simplicity
- Kubernetes-native automation
- Vendor compatibility
- Operator support
- Tiny footprint
- Zero clustering overhead
This is the first time Kubernetes at the edge delivers more value than it costs.
Born for the industrial edge, equally at home in the datacentre
We introduced KubeSolo for the Industrial Edge because that’s where the gap hurt the most. Edge devices running Docker needed Kubernetes compatibility to consume modern software, but they also needed to remain standalone and simple.
It turns out the same pattern exists in datacenters too.
Many enterprises run hundreds or thousands of standalone Docker hosts. Their architectures depend on application-level high availability, not infrastructure-level clustering. They don’t want a full Kubernetes cluster on every server, they just need the Kubernetes API to run modern software.
For them, replacing a Docker host with a KubeSolo host is the easiest upgrade path imaginable.
- No architectural redesign
- No move to clustering
- No change in operational model
Just a future-aligned, Kubernetes-native runtime.
The bottom line: Modernize your runtime, not your architecture
K2D showed us there was value in making Docker “speak Kubernetes”... but it also showed us translation wasn’t enough. The ecosystem had already moved.
KubeSolo is the answer to that shift.
You keep:
- your single-server simplicity
- your existing HA strategy
- your node-centric workflows
- your operational independence
You gain:
- the Kubernetes API
- CRDs, Operators, Helm
- vendor compatibility
- a future-aligned path forward
- all without a cluster
This is why Kubernetes at the edge finally makes sense - because KubeSolo makes it possible.



